
Команда загрузила 200 регламентов в Chroma и спросила про исключение из политики возвратов. Бот уверенно ответил неверно: retrieval вернул чанк «возвраты разрешены», а «кроме акционных билетов» осталось в соседнем куске. Знакомая боль демо RAG — уверенная ерунда без ссылки на источник. Ниже workflow 2026: документы → векторная база → ответы с цитатами и eval на golden set. Вы дойдёте от PDF до проверяемого бота без магии «векторная БД за вечер».
TL;DR / Быстрый инсайт: RAG (Retrieval-Augmented Generation) — нейросеть отвечает по найденным фрагментам документов, а не «из головы». Схема: PDF/DOCX → чанки 300-512 токенов, overlap 10-20% → эмбеддинги в pgvector или Qdrant → hybrid + rerank → ответ с цитатой. Тренд «убить RAG длинным контекстом» в проде откатывается. «rag система» в Вордстате — 2125 показов/мес (июнь 2026).
RAG — конвейер: текст режется на чанки, превращается в эмбеддинги (числовые «отпечатки смысла») и кладётся в векторную базу — хранилище, где поиск идёт по смыслу, а не по точному слову. Вопрос пользователя → похожие чанки → шпаргалка для языковой модели (LLM). Кривая шпаргалка = уверенный неверный ответ, даже если модель «умная».
Я пробовал заменить RAG длинным контекстом: на демо сработало, в проде — устаревшие документы, ответы не тому отделу и галлюцинации при пустом retrieval. На Habr в 2026 описывают тот же откат: «вставим весь корпус в промпт» ломается на свежести, правах доступа и стоимости. Снова строят retrieval-слой с eval, а не один гигантский запрос.
Решите, когда RAG обязателен, а когда хватит длинного контекста

Спор 2026: «зачем векторная БД при контексте на миллион токенов?» Long context (длинный контекст в одном запросе к LLM) годится для пилота на 2-3 файлах. RAG нужен, когда важны свежесть регламентов, ACL (разграничение доступа по ролям), аудит «откуда взялся ответ» и предсказуемая стоимость токенов. На практике команды фиксируют критерии в таблице ниже и не спорят теорией.
| Ситуация | Длинный контекст | RAG + векторная БД |
|---|---|---|
| До 100 страниц, один отдел | Быстрый пилот | Избыточен на старте |
| Сотни PDF, разные права | Нет фильтра по пользователю | Metadata filters + tenant |
| Регламенты обновляются часто | Риск устаревшего промпта | Переиндексация новых чанков |
| Нужна цитата файла/раздела | Модель не доказывает источник | Chunk ID в логах |
Делайте: golden set из 10-15 вопросов до выбора архитектуры. Не делайте: поднимать vector-кластер, если корпус — один файл на месяцы.
Разбейте регламенты на чанки без потери исключений
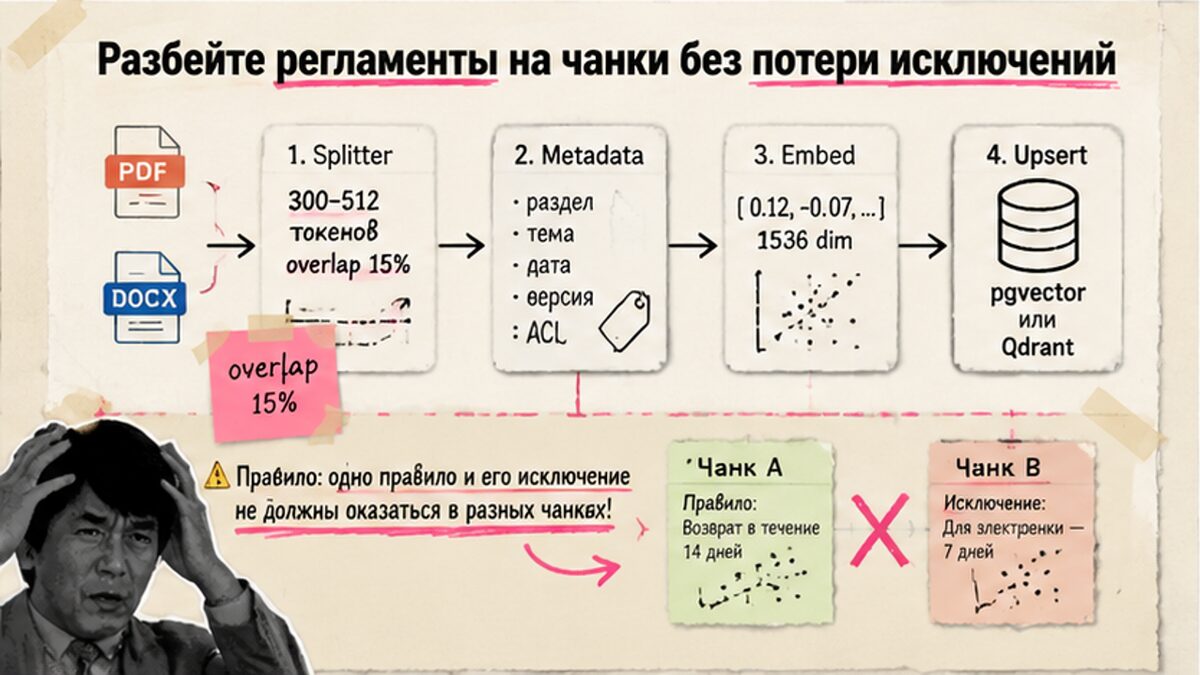
Типичная ошибка — резать текст без overlap. Правило и исключение («кроме акционных билетов») в разных чанках — retrieval находит неполный фрагмент. После чанкинга 400 токенов + overlap 15% точность выросла с 4/10 до 9/10 на том же golden set.
Схема ingestion:
PDF/DOCX → парсинг → RecursiveCharacterTextSplitter 300-512 токенов, overlap 10-20% → metadata (source, section) → эмбеддинги → upsert
- Соберите golden set — 10-15 вопросов с эталоном и разделом-источником.
- Распарсьте файлы с заголовками; для DOCX сохраняйте структуру в metadata.
- Настройте splitter — 300-512 токенов, overlap 10-20% (n8n Docs: 200-500 tokens).
- Добавьте префикс с названием документа и раздела в каждый чанк.
- Проверьте границы вокруг правил с исключениями — при разрыве увеличьте overlap.
На GitHub обсуждают: разный chunker = разные ответы на одних данных. Делайте: один splitter на ingest и query. Не делайте: менять размер чанка без повторного eval.
Сравните pgvector, Qdrant и Chroma под ваш PoC
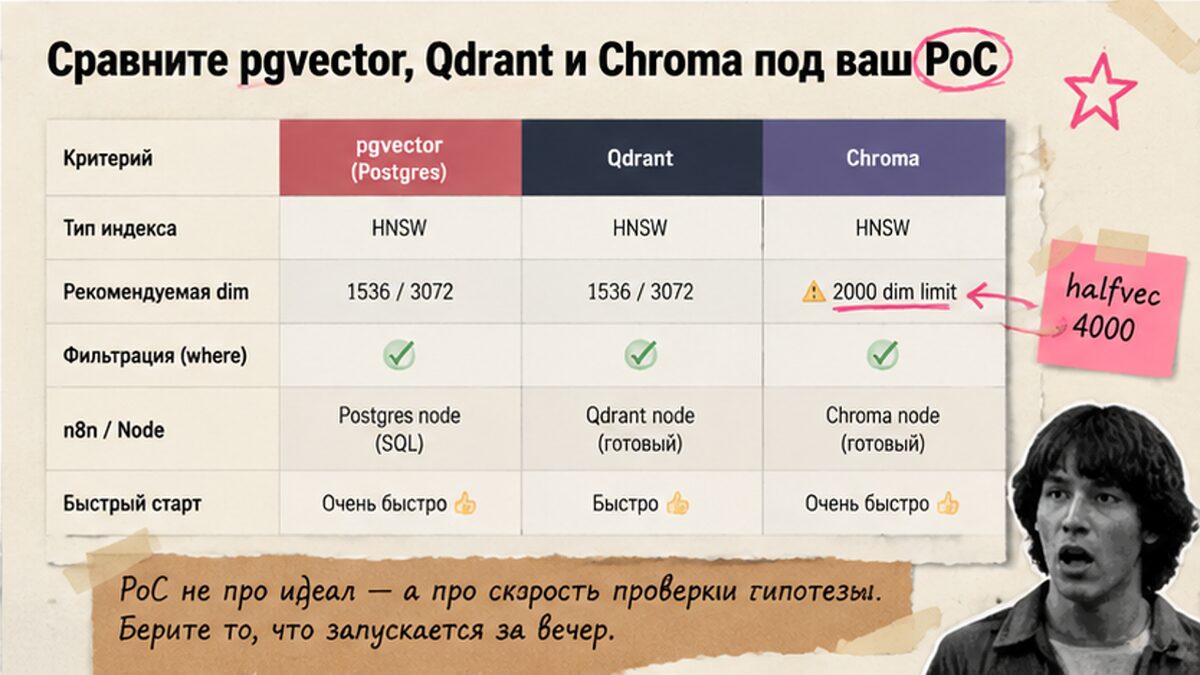
Для локальной rag системы берут Qdrant в Docker или Chroma. При готовом Postgres — pgvector рядом с бизнес-данными. Подводный камень: HNSW в pgvector лимитирован 2000 dim для vector; text-embedding-3-large (3072) без halfvec не проиндексируется.
| Критерий | pgvector | Qdrant | Chroma |
|---|---|---|---|
| Старт PoC | Postgres + расширение | Docker, batch upsert | Минимум кода |
| n8n | PGVector node | Qdrant node | Community nodes |
| HNSW dim | 2000 (halfvec 4000) | По коллекции | По backend |
| Когда | Есть Postgres, ACL в SQL | Отдельный vector-сервис | Быстрый тест на 200 PDF |
Для pgvector: CREATE INDEX … USING hnsw (embedding vector_cosine_ops), m=16, ef_construction=64. Делайте: одна embedding-модель везде. Не делайте: смену модели без переиндексации.
Подключите эмбеддинги, HNSW и гибридный поиск BM25+vector
Чистый vector top-k пропускает артикулы, коды ошибок и фамилии — семантика «похоже», но токен не совпал. Гибрид BM25 (классический полнотекстовый поиск по словам) + vector с filters (tenant, doc_type) ловит запросы вроде «ошибка E-1047» или «п. 3.2.1 регламента». Production-практика 2026: retrieve k=15-20, rerank до 4-6 чанков в промпт; recall@5 часто пик на 600-900 токенах суммарного контекста.
Эмбеддинги превращают абзац в вектор чисел; похожие по смыслу тексты оказываются рядом. HNSW — индекс для быстрого поиска ближайших соседей. Без него на десятках тысяч чанков каждый запрос будет тормозить и съедать бюджет на ожидание.
Делайте: логируйте similarity и chunk IDs. Не делайте: класть все 20 чанков в промпт без rerank.
Соберите retrieval с rerank и запретом галлюцинаций
Цепочка LangChain: load → split → embed → vector store → retriever → generation. System prompt: только по контексту, цитата источника, при пустом retrieval — «в базе нет данных».
Workflow запроса:
Вопрос → hybrid (BM25 + vector, top-k 15-20) → rerank до 4-6 → LLM с цитатами → лог chunk IDs
Шесть точек отказа enterprise RAG: chunk boundary, version drift, embedding mismatch. Делайте: порог отказа при низкой similarity. Не делайте: просить модель додумать при слабом match.
Запустите pipeline в Python или n8n и проверьте golden set
Две дорожки с одной логикой. Python (LangChain): скрипт ingestion + retriever chain, structured output с полем source — удобно для rag система python и кастомного API. n8n: отдельные workflow для загрузки и для запросов (так в документации n8n по RAG); QA Chain для строгого режима «только база» или AI Agent с vector store как tool. Типичная ошибка в реальном проекте — разные embeddings или splitter в dev на Python и в prod в n8n: ответы расходятся, а команда ищет «баг модели».
- Ingestion: Document Loader → Splitter → Embeddings → Vector Insert.
- Query: Webhook/Chat → Vector Tool → Agent с prompt «только контекст + цитата».
- Обновление: удалить старые chunk ID по source, upsert новые.
- Eval: 10-15 вопросов golden set, время и стоимость до/после rerank.
- Мониторинг: алерт, если успех ниже 8/10 после смены модели.
Связка с автоматизацией: ИИ-агенты в n8n, dev-среда — MCP в Cursor. В клубе Make.com разбираем цепочки документы + API без команды разработчиков.
Как понять, что RAG-система действительно работает
Критерий готовности измеримый. На 10-15 вопросах golden set система отвечает с указанием файла и раздела; в 8 из 10 случаев найденный чанк в логах подтверждает ответ. При пустом retrieval модель отказывается галлюцинировать — это обязательный тест, не опция. В таблице до/после зафиксированы время ответа и стоимость запроса: вы видите эффект rerank и гибридного поиска, а не субъективное «стало лучше».
Если метрика просела после обновления корпуса — сначала смотрите retrieval (какие chunk ID пришли), потом generation. Часто «галлюцинация» — на самом деле промах поиска: модель честно додумывает слабый контекст.
Что делать дальше
- Добавьте в golden set запросы с точными кодами — проверьте hybrid.
- Webhook в n8n на переиндексацию при новом PDF.
- Лог chunk IDs в боте поддержки — менеджер видит источник.
- Ежемесячный eval после смены embedding или регламентов.
Agentic RAG имеет смысл после стабильного eval — иначе умножите хаос.
Материал проверен: эксперт Елена Ковалева (Главный эксперт по SEO/GEO).
Достоверность данных: все статистические показатели и ключевые фразы верифицированы по данным Яндекс Вордстат на июнь 2026 года.
Частые вопросы
Как сделать rag систему с нуля без разработчиков?
n8n: два workflow, Chroma или PGVector, splitter 300-400 токенов, golden set 10 вопросов. В прод — только после 8/10 ответов с цитатой.
Чем RAG отличается от fine-tuning?
Fine-tuning вшивает знания в модель и дорого обновляется. RAG подставляет актуальные чанки — переиндексация за минуты.
Какой размер чанка для русских PDF?
300-512 токенов, overlap 10-20%. Теряются исключения — overlap 15% или заголовок раздела в чанке, затем eval.
pgvector или Pinecone в 2026?
Self-host: pgvector или Qdrant на VPS. Pinecone — если нужен managed и нет on-premise требований.
Нужен ли rerank при HNSW?
Да. HNSW ищет кандидатов, rerank сортирует top-20 по вопросу. Без rerank — «похожие, но мимо» чанки.
Можно ли заменить RAG длинным контекстом?
На малом корпусе — да. На сотнях документов с ACL и аудитом — нет; смотрите таблицу в начале статьи.











