
Операционист логистики подключил «умный OCR» к папке входящих: текст из сканов появился, но в МойСклад суммы и реквизиты всё равно переносят руками. Разово прогнали счёт через ChatGPT — модель «додумала» ставку НДС 22% вместо 20%. Типичная боль первички: распознавание есть, а цепочки «скан → поля → CRM» нет. За 1–2 недели на n8n или Make можно собрать конвейер intake → OCR → LLM в JSON → валидация → проверка человеком → экспорт в учётку — без тяжёлой СЭД и без штатного разработчика.
TL;DR / Быстрый инсайт: Люди чаще ищут «ии для распознавания документов» (161 показ/мес), чем «автоматизацию электронных документов» (109) — им нужен путь до CRM, а не вендор ЭДО. Оптимален гибрид: OCR на массовых счетах, LLM/VLM на нестандартных макетах. Обязательны JSON-схема, валидация ИНН/КПП/НДС и human-in-the-loop перед 1С. Пилот на 30–50 счетах: ≥90% верных обязательных полей.
Это не обзор двадцати нейросетей и не ROI +380%. Одна мастерская: один тип документа (счета) от файла до строки в CRM. По Вордстат на июнь 2026 ядро «автоматизация обработки документов» — 599 показов/мес, рядом «ии для распознавания документов» — 161 и «автоматизация процессов обработки документов» — 141. В выдаче много ТОП-20 сервисов без JSON-схемы и очереди проверки — отсюда этот гайд.
Directum в трендах IDP 2026: VLM (модели, которые «смотрят» на страницу и понимают смысл) сильны на договорах, на массовых счетах классический OCR/IDP быстрее — нужен роутинг по типу файла. Microsoft в reference architecture описывает тот же скелет: email intake → extract → auto-check → human review → feedback. Переносимо в n8n/Make за выходные.
Выберите пилотный тип документов и KPI до покупки СЭД

Типичная ошибка — купить ЭДО (электронный документооборот) и ждать автозаполнения CRM. ЭДО закрывает юридический обмен с контрагентом; сканы из почты и фото накладных — отдельный трек. Начните со счетов или актов: 30–50 эталонных файлов, список полей (ИНН, КПП, дата, номер, сумма, ставка и сумма НДС, банковские реквизиты). В реальном проекте без этого списка команда спорит «какие поля обязательны» вместо настройки узлов.
KPI пилота: ≥90% обязательных полей верны; низкий confidence → review, не учёт; после approve данные в CRM/Sheets/1С за ≤5 минут; журнал doc_errors для доработки промптов. В результате вы получите измеримый ориентир до покупки СЭД.
Делайте: зафиксируйте один тип документа и список полей до настройки узлов. Не делайте: покупать ЭДО, ожидая автозаполнения CRM из сканов почты.
- Один тип документа и 30–50 тестовых файлов.
- Список обязательных полей и правил (НДС 0/10/20%).
- Система назначения: МойСклад, amoCRM, 1С или таблица.
- Цель ≥90% точности, срок пилота 1–2 недели.
- Журнал ошибок с первого дня.
- Шаг приёмки: проверьте 10 файлов вручную до автозаписи в учёт.
Соберите intake и OCR-ветку: цепочка, а не один узел
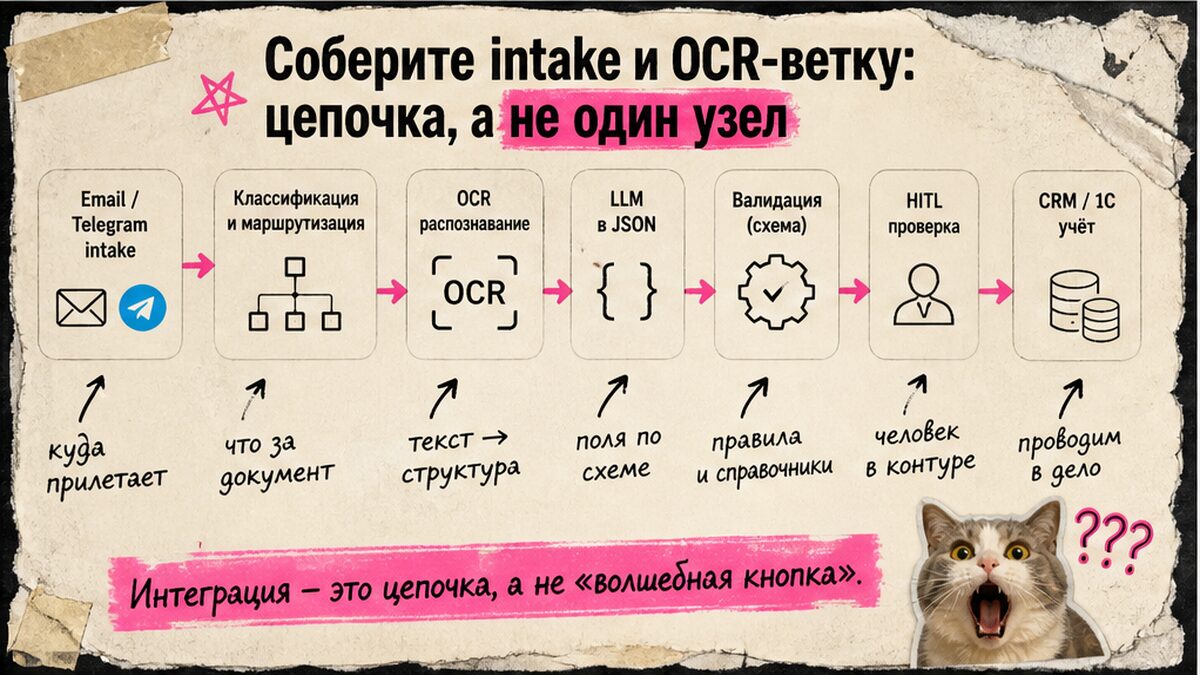
OCR считывает текст со скана, но не структуру. Ошибка — один OCR-узел и ручной копипаст. Архитектура n8n: intake → validation → extraction → decision → review → output → audit.
Схема:
Drive/email/webhook → archive + document_queue → роутинг → OCR/парсер PDF → текст + confidence → LLM JSON → validation → HITL или export → CRM → audit log
Триггер в n8n или Make: копия в archive, статус received в document_queue. Роутинг: текстовый PDF — парсер; скан — Google Vision, Tesseract или Mistral OCR (mistral-ocr-latest, markdown-выход и confidence scores); незнакомый layout — LLM/VLM. Webhook — это URL-адрес, на который система сама шлёт файл при загрузке: удобно для формы на сайте или бота в Telegram.
На GitHub invoice-parse OCR отделён от LLM — в 10–50 раз дешевле, чем кормить модель картинками. IDP (intelligent document processing) — «умная» обработка: не просто текст, а поля с уверенностью. n8n здесь оркестратор — дирижёр, который зовёт OCR, LLM и CRM по очереди, не переделывая всю IT-архитектуру.
| Тип файла | Инструмент | Если не хватает |
|---|---|---|
| Текстовый PDF из ЭДО | Парсер без OCR | Кривая вёрстка — LLM по тексту |
| Скан счёта | Mistral OCR, Vision, Tesseract | Плохой скан — HITL |
| Договор | LLM/VLM + схема полей | Массовые счета — IDP |
Извлеките поля в JSON: схема жёстче промпта

LLM без JSON Schema «додумывает» ИНН и НДС. Схема — фиксированная форма: модель заполняет ячейки, не придумывает реквизиты. Промпт: «Только факты из текста. Не вычисляй НДС, если ставка не указана.» Узел Code парсит ответ; кэш по SHA-256 хешу файла. Используйте strict JSON и добавьте узел, который падает с ошибкой, если JSON битый.
Пример JSON Schema для счёта:
{ «invoice_number»: «string», «supplier_inn»: «string», «total_amount»: «number», «vat_rate»: «0|10|20|null», «vat_amount»: «number|null» }
На практике дешевле OCR → текст → LLM, чем картинка в модель на каждый документ. LLM (большая языковая модель, «ChatGPT в API») здесь не собеседник, а парсер: на входе сырой текст счёта, на выходе JSON для импорта. Делайте: уберите вычисление НДС из промпта. Не делайте: давать модели свободу формулировок без схемы.
Поставьте валидацию и policy gates до учёта
Confidence OCR — не единственный фильтр. InvoiceMind на GitHub: policy gates RECEIVED → VALIDATED → EXTRACTED → NEEDS_REVIEW вместо слепого доверия к score. Правила: regex ИНН (10 или 12 цифр) и КПП (9 цифр), сверка итога с суммой позиций с допуском копейки, whitelist НДС 0/10/20%, обязательные поля не пустые. Проект invoice-processing-automation отправляет в human review всё со score <0,7 с audit trail. Настройте validation до экспорта — так вы избегаете «тихих» ошибок в 1С.
Часто ломается запятая в сумме: OCR читает «15,000» как английский формат — regex ловит раньше бухгалтера. В учёт попадают только approved записи; всё остальное висит в очереди, а не в 1С.
Включите human-in-the-loop перед записью в CRM
Без человека автономный ИИ закрывает меньше 2,5% сложных неструктурированных задач — HITL (human-in-the-loop, человек в контуре) обязателен. Review-таблица в Google Sheets или лёгкий экран: колонки approve, reject, edit, комментарий, ссылка на файл в archive. Бухгалтер правит поля в одном месте; только после approve — HTTP-запрос к CRM, МойСклад или 1С.
Дубликаты отсекайте по SHA-256 хешу файла до OCR — повторная загрузка того же счёта не должна создавать вторую оплату. Reject с причиной в doc_errors («галлюцинация НДС», «ИНН не прошёл regex») — топливо для еженедельного разбора промптов. Так вы не ищете, кто занёс неверную сумму: в audit log видно файл, версию промпта и решение человека.
Интегрируйте экспорт через n8n или Make
Оркестратор связывает узлы без замены СЭД (системы электронного документооборота): триггер → validation → ветка IF approved → API CRM или строка в Sheets → Telegram/Slack при ошибке валидации или дубликате. API — «розетка» программы: отправляете JSON с полями, CRM создаёт карточку поставщика и счёт. В Make — модуль HTTP или нативная интеграция amoCRM; в n8n — Webhook и Code. Для 1С часто идут через промежуточную таблицу или готовый коннектор — главное, чтобы поля прошли validation до вызова.
Пилот на одном типе документов укладывается в 1–2 недели: не надо менять всю учётную политику. Сначала Sheets как буфер, потом прямой экспорт — так проще откатить ошибку. Запустите workflow на тестовой папке, проверьте API-ключ CRM и только потом включайте автозапись.
Похожие цепочки с OCR и HTTP разбираем в клубе по Make — блюпринты и эфира два раза в неделю, без найма разработчика.
Чек-лист запуска и критерии успеха
- ПДн: обезличивание перед облачным LLM при необходимости.
- Retention archive и audit по 152-ФЗ.
- Еженедельный разбор review и doc_errors.
- A/B OCR на «битых» сканах.
- Алерты при validation fail и дубликате.
- ЭТрН с 01.09.2026 — контекст для логистики, не замена счётного пайплайна.
- ЭДО где закон требует; n8n — для сканов из почты.
- Версия промпта и схемы в git или таблице.
Пилот удался, если: ≥90% полей верны на тестовой выборке; спорные документы не в учёте без approve; от файла до CRM ≤5 минут; журнал ошибок показывает, что чинить. Измеримо за две недели.
Редакционная проверка: материал сверил Артур Хорошев (CEO Maya AI, практик n8n/Make и IDP-workflow).
Источники цифр: показатели Яндекс Вордстат и тренды IDP 2026 перепроверены на дату исследования — 16 июня 2026 года.
Частые вопросы
Как автоматизировать счета и накладные без программиста?
Make или n8n: Drive → OCR → LLM + JSON → validation → review → API CRM. Код только в узлах regex/parse — можно сгенерировать в Cursor. Пилот на одном типе — 1–2 недели.
Чем OCR+LLM отличается от RAG для документов?
RAG отвечает на вопросы по архиву. Для счёта нужен extraction: ИНН, сумма, НДС в JSON с правилами. OCR даёт текст, LLM раскладывает по схеме, regex проверяет цифры.
Какие сервисы распознают PDF в структурированные данные?
DIY: Mistral OCR, Google Vision, Tesseract + LLM в n8n/Make. Enterprise: AI Builder (Power Automate + review). На массовых счетах хватает OCR+LLM; на договорах — гибрид с VLM.
Нужно ли ЭДО, если есть OCR?
ЭДО — где закон требует электронный обмен. OCR+workflow — скан из почты → поля в учёт. Ветки параллельны и нормальны.
Модель путает НДС — что делать?
Уберите вычисление из промпта, whitelist 0/10/20%, сверка vat_amount с total. Ошибки в doc_errors разбирайте еженедельно.
Make или n8n?
Make быстрее старт с Google Sheets и CRM в облаке. n8n гибче для self-hosted и Code. Оба подходят под intake → OCR → LLM → HITL → export.
Прогоните 30 тестовых счетов, замерьте точность, потом автозапись в учёт. Автор: Артур Хорошев. Вопросы по Make — @maya_pro.










