
Маркетолог слышал, что без llms.txt сайт будто пропадёт из ответов нейросетей, добавил случайную строку в robots.txt, выгрузил туда весь блог и стал ждать цитат. Боль знакомая: тренд GEO/AEO давит, а что реально положить в файл – непонятно. Рабочий ответ спокойнее: собрать короткую карту важных страниц, выложить её в корень сайта и проверить без ошибок.
TL;DR / Быстрый инсайт: llms.txt – не волшебная кнопка для Google, ChatGPT или Perplexity, а подсказка для AI-агента: какие страницы сайта читать в первую очередь. Делайте файл коротким, в Markdown, с описаниями ссылок и разделом Optional для второстепенного. Если сайт небольшой, хватит 10-30 URL; llms-full.txt нужен в основном документации, API и большим базам знаний.
Тут важный конфликт. Google Search Central пишет, что специальные AI-файлы не нужны для AI Overviews и не улучшают ранжирование. Зато Chrome Lighthouse в категории Agentic Browsing уже смотрит, как сайт отвечает на /llms.txt: отсутствие файла пока N/A, а серверная ошибка – проблема.
Факт от Ahrefs охлаждает ожидания: в мае 2026 они изучили 137 210 доменов и увидели, что 97% валидных llms.txt не получили ни одного запроса. Значит, задача не «заставить ИИ цитировать сайт», а сделать аккуратную навигацию.
Разведите SEO-обещание и реальную задачу файла

llms.txt простыми словами – это текстовый файл в корне сайта, например https://domain.ru/llms.txt, где вы объясняете сайт и даёте выбранные ссылки. AI-агент – программа, которая открывает страницы и собирает информацию для ответа. Файл не командует агентом, а подсказывает: «вот главные двери, начни отсюда».
Типичная ошибка – продавать llms.txt как гарантию попадания в ответы нейросетей. Такой гарантии нет. На практике файл стоит делать как low-cost housekeeping: небольшую работу по порядку в данных, которую можно выполнить за 30-60 минут.
Решение для старта: перед созданием файла запишите одну честную цель: «помочь AI-агенту быстрее найти ключевые страницы сайта». Если цель звучит как «получить рост трафика из Google AI», вернитесь к обычному SEO, качеству контента, schema и внутренней перелинковке.
Отберите 10-30 URL вместо выгрузки всего сайта
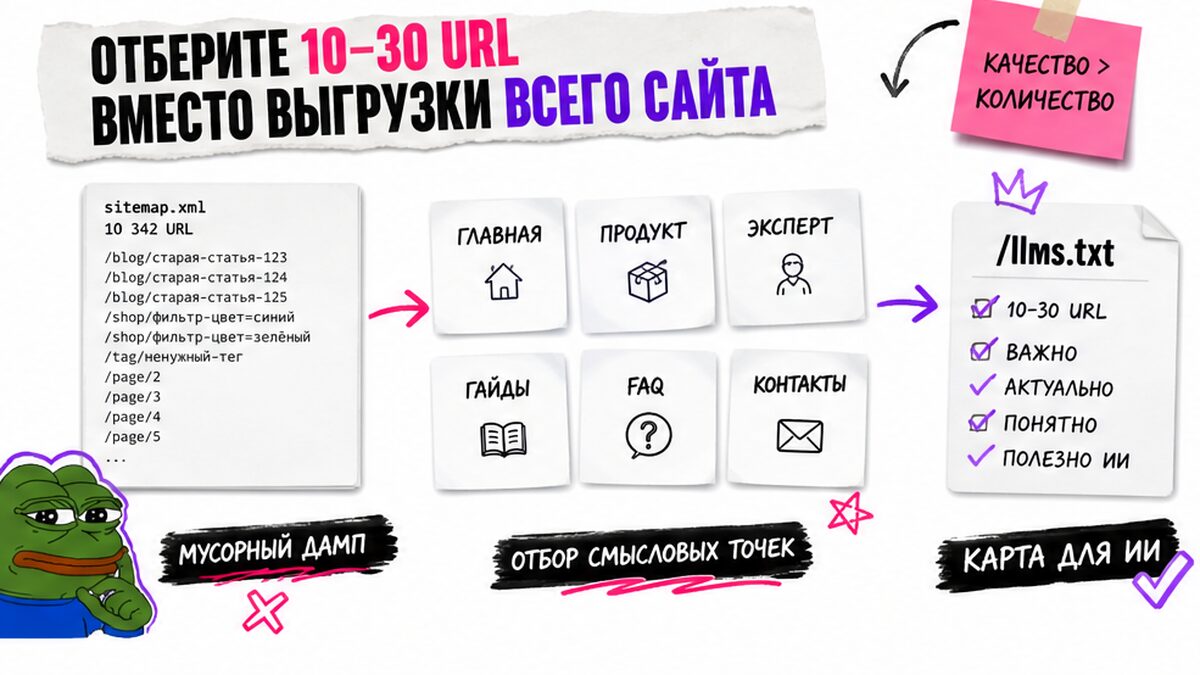
Главная боль владельца сайта – сотни страниц и страх выкинуть что-то важное. Но llms.txt не обязан быть копией sitemap.xml. Например, для сайта услуг туда попадают главная, профиль эксперта, страницы продукта, 3-7 сильных гайдов, кейсы, FAQ, контакты и условия.
- Шаг 1: Выпишите страницы, которые отвечают на вопрос «кто вы и чем полезны».
- Шаг 2: Добавьте страницы продукта, услуги, тарифа или формата работы.
- Шаг 3: Выберите гайды, которые чаще всего объясняют вашу экспертизу.
- Шаг 4: Оставьте кейсы и отзывы только если они живые и не похожи на рекламный шум.
- Шаг 5: Уберите теги, пагинацию, архивы, дубли, служебные страницы и старые новости.
- Шаг 6: Проверьте, что каждая ссылка имеет смысл без соседнего контекста.
В реальном проекте удобно вести таблицу: URL, роль страницы, описание, приоритет, дата проверки. Если строчка не проходит вопрос «зачем агенту это читать?», её лучше не добавлять.
Соберите llms.txt по Markdown-шаблону

Спецификация на llmstxt.org предлагает формат Markdown. Это обычный текст с понятными знаками: решётка для заголовка, квадратные скобки для названия ссылки, круглая скобка для адреса.
Минимальная структура: H1 с названием сайта, короткая цитата-описание, несколько H2-разделов и списки ссылок. Раздел Optional нужен для материалов, которые можно пропустить, если агенту нужен короткий контекст.
Шаблон llms.txt:
# Название сайта
> Коротко: что делает компания, кому помогает и чем отличается.
## Основное
— [Главная](https://domain.ru/): кто мы, чем занимаемся, кому полезны.
— [Продукт](https://domain.ru/product/): что входит в услугу или продукт.
— [Об авторе](https://domain.ru/about/): экспертиза, опыт, публичные профили.
## Гайды и инструкции
— [Как выбрать решение](https://domain.ru/blog/guide/): практический материал для клиента.
— [FAQ](https://domain.ru/faq/): ответы на частые вопросы перед покупкой.
## Optional
— [Архив блога](https://domain.ru/blog/): дополнительные материалы, не обязательные для первого чтения.
Не пишите длинные рекламные аннотации. Достаточно одного предложения после двоеточия: что находится на странице и зачем её читать.
Не смешивайте robots.txt, sitemap.xml и llms.txt
Частый вопрос – нужно ли добавить llms.txt в robots.txt. Можно указать ссылку как подсказку, но это не делает файл обязательным. robots.txt похож на охранника у двери: он говорит ботам, куда не ходить. sitemap.xml похож на каталог комнат. llms.txt – записка администратору: «если пришёл за сутью сайта, начни отсюда».
| Файл | Главная задача | Чего не делает |
|---|---|---|
| robots.txt | Даёт правила доступа для ботов | Не объясняет смысл страниц |
| sitemap.xml | Перечисляет URL для индексации | Не выбирает лучшие страницы для AI-ответа |
| llms.txt | Курирует контекст и важные ссылки | Не блокирует, не ранжирует и не гарантирует цитирование |
Практическое правило: не удаляйте robots.txt и sitemap.xml ради нового файла. Если добавляете строку о llms.txt в robots.txt, это указатель, а не техническая магия.
Выложите файл в корень сайта и проверьте отдачу
Файл должен открываться по адресу /llms.txt. Для WordPress его обычно кладут в корень хостинга или отдают через сервер. Для статических сайтов, Next.js, Astro и Vite часто достаточно папки public. Для CMS и конструкторов вроде Tilda нужен путь без HTML-обёртки.
Проверьте, что сервер отдаёт обычный текст: text/plain или text/markdown. Часто ломается мягкий 404: вы видите страницу с дизайном, а внутри это HTML-шаблон ошибки. AI-агенту такой ответ бесполезен.
- Откройте https://domain.ru/llms.txt в браузере.
- Убедитесь, что видите текст Markdown, а не страницу темы.
- Проверьте абсолютные URL и отсутствие битых ссылок.
- Посмотрите, нет ли 5xx-ошибки сервера при запросе файла.
- Сохраните дату последней ручной проверки в своей таблице.
Решите, нужен ли llms-full.txt и генератор
llms-full.txt – не «улучшенная версия для всех». Это большой файл с документацией, справочником API, инструкциями, иногда набором Markdown-страниц. API на пальцах – меню команд, через которое одна программа просит другую что-то сделать.
OpenAI и Anthropic публикуют LLM-friendly файлы для документации, потому что там много справочных страниц и инструкций. Обычному лендингу, локальному бизнесу или небольшому блогу чаще достаточно короткого llms.txt. Типичная ошибка – сгенерировать гигантский llms-full.txt и забыть обновлять его.
Если сайт большой, подключайте генератор. По GitHub-сигналам из research, llmoptimizer работает с sitemap и статическими сборками, а docusaurus-plugin-llms помогает документационным сайтам. Для не-программиста смысл простой: генератор пересобирает файл по правилам, чтобы не копировать ссылки руками.
Настройте поддержку и измеряйте факты, а не надежду
После публикации включите файл в редакционный процесс: новая важная страница → короткое описание → проверка ссылки → обновление /llms.txt → запись даты. Если у вас контент-завод, это можно автоматизировать через Make.com: брать approved-страницы из таблицы, собирать Markdown и отправлять файл на сайт. Такой workflow разбирают в курсе Make.com + вайбкодинг, но базовый принцип работает и вручную.
Рабочий workflow: таблица приоритетных URL → ручная или автоматическая сборка Markdown → публикация в корень сайта → проверка HTTP 200 → ежемесячный просмотр логов и актуальности ссылок.
Как понять, что задача решена: файл открывается по https://domain.ru/llms.txt, внутри есть H1, короткое описание, 2-5 разделов, ссылки с пояснениями и Optional. Он не конфликтует с robots.txt, не заменяет sitemap.xml, не отдаёт HTML-ошибку, а в Lighthouse нет серверной ошибки. В логах могут быть обращения ботов, но их отсутствие не значит, что файл сделан плохо.
Если хочется обсудить автоматизацию без кода, можно заглянуть в Telegram «Ковчег»: там разбирают связки Make, таблиц, сайтов и AI-агентов.
Материал проверен: Артур Хорошев, CEO Maya AI и автор курса по Make.com и вайбкодингу. Факты сверены с llmstxt.org, Google Search Central, Chrome Lighthouse, GitHub-релизом Lighthouse v13.3.0 и исследованием Ahrefs за май 2026. Ключевые фразы и спрос проверены по Яндекс Вордстат на 16 июня 2026 года.
Частые вопросы
Как создать llms.txt для сайта без программиста?
Соберите 10-30 важных ссылок, сгруппируйте их по задачам, напишите короткие описания и сохраните файл как llms.txt. Затем выложите его в корень сайта и откройте https://domain.ru/llms.txt.
Нужно ли добавлять llms.txt в robots.txt?
Можно добавить строку-ссылку, но это не обязательное правило. robots.txt управляет доступом ботов, а llms.txt объясняет, какие страницы стоит прочитать в первую очередь.
Поможет ли файл llms txt попасть в ответы нейросетей?
Гарантии нет. Google Search говорит, что специальные AI-файлы не нужны для AI Overviews и не дают бонуса ранжирования. Делайте llms.txt как карту сайта для AI-агентов, а не как обещание трафика.
Чем llms.txt отличается от sitemap.xml?
sitemap.xml перечисляет URL для поисковой индексации. llms.txt выбирает меньше страниц и добавляет пояснения: что лежит по ссылке и зачем это читать. Поэтому не копируйте sitemap полностью.
Когда нужен llms-full.txt?
Он нужен, если у вас большая документация, API, база знаний или продуктовый справочник. Для небольшого сайта услуг, лендинга или блога чаще достаточно короткого llms.txt.
Как часто обновлять файл llms.txt?
Обновляйте его при публикации ключевой страницы и делайте ревизию раз в месяц. Удаляйте устаревшие URL, проверяйте описания и не паникуйте, если обращений к файлу пока нет.










