
IT-директор слышит: «локальная нейросеть бесплатна и безопасна». Ставит Ollama на ПК с 8 ГБ видеопамяти, тянет 32B-модель, открывает порт 11434 в LAN «для коллег» – и через неделю ловит утечку данных в логах при ответах медленнее облака. Аналитик в агентстве сделал OLLAMA_HOST=0.0.0.0 для n8n в Docker – коллега из соседнего VLAN увидел список моделей без пароля. Ниже – workflow от сценария до API и закрытого контура.
TL;DR / Быстрый инсайт: Ollama – это «движок» для локальных языковых моделей (LLM) на вашем ПК или мини-сервере. Для бизнеса выгоден на рутине: суммаризация внутренних документов, черновики писем, классификация тикетов. Запрос «ollama» в Вордстате – 32 669 показов/мес, «локальные нейросети» – 5 854. Старт: qwen3:8b на 8 ГБ VRAM, проверка ollama ps + nvidia-smi, API на localhost:11434, n8n через host.docker.internal. Порт 11434 без auth в интернет не выставлять.
Локальная LLM генерирует текст на вашем железе, без отправки промптов в ChatGPT. Self-hosted – данные не уходят на чужой сервер. API – «разъём», через который n8n, Cursor или Python просят модель ответить. Ollama 0.30 (июнь 2026) перешла на llama.cpp, но ollama ps может показать «100% GPU», пока nvidia-smi на нуле (issue #13814). Диагностика – сверка двух команд, не переустановка.
Выберите один сценарий: когда Ollama выгоднее облака
Главная ошибка – ставить Ollama «потому что модно», без задачи. На практике локальная модель окупается на повторяющейся рутине: краткие выжимки из регламентов, черновики писем клиентам, сортировка обращений по темам. Облачный API (ChatGPT, Claude) оставьте для сложного reasoning – юридические формулировки, стратегия, креатив с высокой ценой ошибки.
Персональные данные в публичном чате – риск по 152-ФЗ. Self-hosted Ollama держит промпты в периметре. Модель не заменяет юриста: на критичных ответах нужен human-in-the-loop – человек проверяет перед отправкой клиенту.
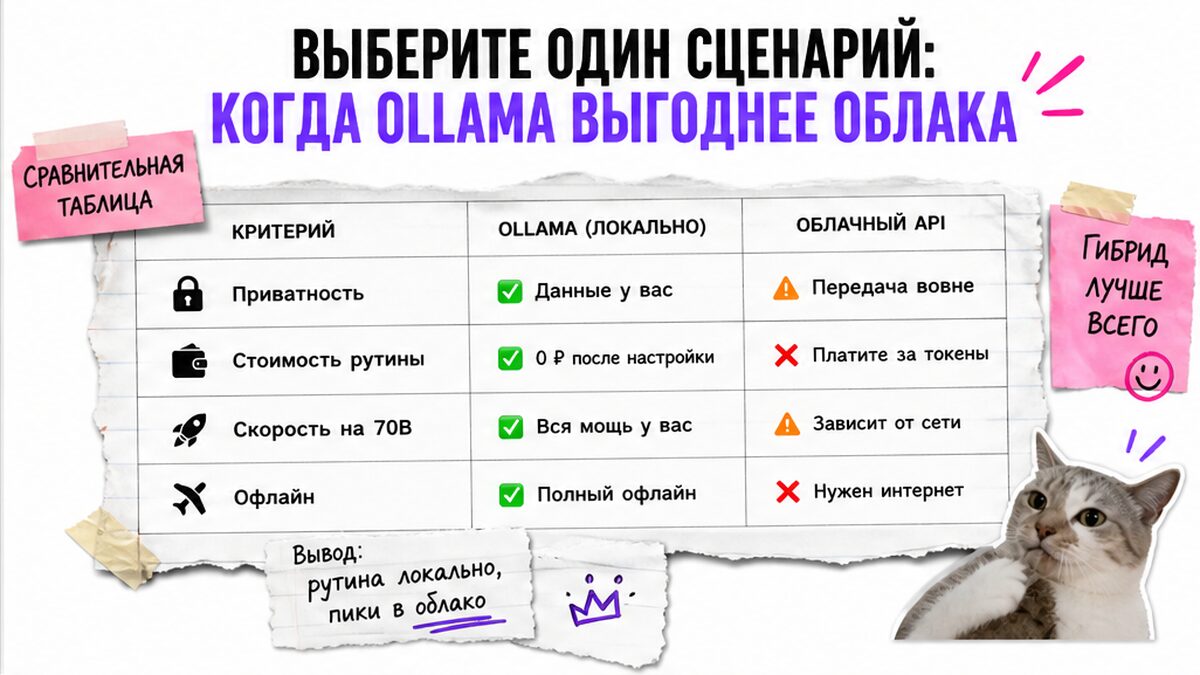
| Критерий | Локальная Ollama | Облачный API |
|---|---|---|
| Приватность | Промпты на своём железе | Данные у провайдера по его правилам |
| Стоимость рутины | Нулевые токены после покупки GPU | Плата за каждый запрос |
| Скорость на 70B | Часто проигрывает без дорогого GPU | Стабильно на стороне дата-центра |
| Офлайн | Работает без интернета | Нужен доступ к API |
Итоговый вердикт: гибрид – рабочая схема. Черновики и классификация – локально; финальный текст для клиента – облако или ручная правка.
Сверьте железо с моделью до команды ollama pull

Типичная боль: ollama pull llama3.1:70b на RTX 3060 12 ГБ. Модель «загрузилась», но ollama ps показал 80% CPU – ответы идут 2 токена в секунду, проект списывают как «локальный ИИ не работает». VRAM (видеопамять GPU) – главный лимит: чем больше модель, тем больше памяти нужно.
| VRAM / RAM | Рекомендуемая модель | Задача |
|---|---|---|
| 8 ГБ VRAM, RAM 16+ ГБ | qwen3:8b или gemma4 Q4 | Суммаризация, русский текст, лёгкий код |
| 16 ГБ VRAM | qwen3:14b Q4 | Более длинный контекст, сложнее инструкции |
| Apple Silicon 32+ ГБ unified | MLX-модели Ollama | Офис на Mac без дискретной NVIDIA |
Qwen3 8B в квантовании Q4_K_M занимает около 5,8 ГБ VRAM при контексте 8k – комфортно на карте 8 ГБ. Запрос «qwen ollama» – 911 показов/мес в Вордстате; для русского и кода это разумный дефолт, а не погоня за MMLU-бенчмарками.
Делайте: сверяйте таблицу VRAM перед pull. Не делайте: тянуть самую большую модель «на вырост».
Установите Ollama и проверьте инференс в терминале

Инференс – простыми словами, «момент, когда модель отвечает на ваш вопрос». Установка: Windows 10+ – инсталлятор с ollama.com/download/windows; Linux – скрипт с ollama.com/install.sh; macOS – приложение с поддержкой Apple Silicon.
- Шаг 1: Установите Ollama и убедитесь, что служба запущена (иконка в трее на Windows или systemctl status ollama на Linux).
- Шаг 2: Скачайте модель: ollama pull qwen3:8b (команда pull – как «скачать веса» модели в локальный кэш).
- Шаг 3: Запустите диалог: ollama run qwen3:8b и задайте тестовый промпт на русском, например «сожми этот абзац в три пункта».
- Шаг 4: Во втором окне терминала выполните ollama ps – ожидайте Processor: 100% GPU, не CPU.
- Шаг 5: Параллельно откройте nvidia-smi. Если GPU пустой, а ollama ps врёт про GPU – уменьшите модель или обновите драйвер CUDA 12.4+.
- Шаг 6: Зафиксируйте скорость: целевые 20–40+ токенов/с на GPU для внутренних задач.
В реальном проекте сначала меньшая модель, потом драйверы. Пока Ollama не предупреждает о CPU fallback (PR #14261), сверяйте ollama ps с nvidia-smi сами.
Подключите OpenAI-совместимый API к n8n и Cursor
API Ollama совместим с форматом OpenAI: тот же endpoint /v1/chat/completions. Base URL: http://localhost:11434/v1/. Поле api_key обязательно в SDK, но Ollama его игнорирует – можно указать любую строку.
Схема интеграции:
Ollama (localhost:11434) → OpenAI-совместимый REST → n8n Ollama credential / Cursor custom endpoint / Python OpenAI SDK
Проверка curl: POST на http://localhost:11434/v1/chat/completions с JSON-телом model и messages – должен вернуться JSON с ответом. Запрос «ollama api» – 782 показа/мес; «ollama openai api» – узкий, но прямой intent.
Типичная ошибка: n8n в Docker не видит Ollama на хосте. Решение из официальной документации: Base URL http://host.docker.internal:11434 и на Linux в docker-compose добавить extra_hosts: host.docker.internal:host-gateway. Тест в n8n: «Connection tested successfully».
Для Cursor: укажите OpenAI-compatible endpoint на локальный URL. Для Python: OpenAI SDK с base_url=http://localhost:11434/v1/. Если автоматизация шире, чем один узел, посмотрите гайд по ИИ-агентам в n8n и подключению MCP в Cursor. Для базы знаний поверх локальной модели пригодится RAG с векторной базой.
Похожие цепочки с Make и n8n разбираем на курсе по автоматизации.
Закройте периметр: порт 11434 без встроенной auth
Ollama не имеет встроенной аутентификации. Открытый OLLAMA_HOST=0.0.0.0 в LAN – как оставить дверь офиса на щеколку: любой в сети может дергать модель и читать логи. В открытых сканерах тысячи таких инстансов.
Делайте: по умолчанию OLLAMA_HOST=127.0.0.1:11434 – только локальные процессы. Для команды – reverse proxy с API key или закрытая mesh-сеть (Tailscale) без публикации порта в интернет. Логи – без сырого PII (персональных данных клиентов).
Не делайте: проброс 11434 на роутере «чтобы поработать из дома». Не смешивайте тестовые промпты с реальными ФИО и договорами в общих логах.
Пройдите чек-лист запуска и зафиксируйте fallback
Успех измеряется не фактом установки, а стабильным SLA на вашей задаче. Критерии готовности:
- ollama run qwen3:8b (или выбранная модель) стабильно отвечает на тестовый промпт.
- ollama ps показывает 100% GPU; nvidia-smi подтверждает загрузку.
- curl на /v1/chat/completions возвращает валидный JSON.
- n8n или скрипт проходит smoke-test одного workflow.
- Порт 11434 не торчит в интернет без прокси.
- Шаг 1: Соберите 20 тест-кейсов из реальных документов (без ПДн в открытом виде).
- Шаг 2: Запишите latency (токены/с) и качество по шкале «можно отправить / нужна правка / мусор».
- Шаг 3: Опишите правило эскалации: при низкой уверенности – облачная модель или человек.
- Шаг 4: Назначьте регламент ollama pull для обновлений модели раз в квартал.
- Шаг 5: Сравните «сэкономленные токены» с амортизацией железа и временем админа.
Локальный ИИ не бесплатен – вы платите железом и часами настройки. На рутине маржа растёт, когда облако остаётся для сложного.
Материал проверен: эксперт Артур Хорошев (CEO Maya AI, автор курса по Make.com).
Достоверность данных: статистика Вордстат (ollama 32 669, локальные нейросети 5 854, ollama api 782) и технические факты Ollama 0.30 верифицированы по официальным docs и GitHub на июнь 2026 года.
Частые вопросы
Как установить Ollama на Windows для бизнеса?
Скачайте инсталлятор с ollama.com/download/windows (Windows 10+), установите, выполните ollama pull qwen3:8b и ollama run для теста на русском. Запрос «установить ollama» – 419 показов/мес, «ollama windows» – 880.
Какие ollama модели выбрать для офиса?
На 8 ГБ VRAM – qwen3:8b или gemma4 Q4 для русского и рутины. На 16 ГБ – qwen3:14b. Не ориентируйтесь на размер в названии: сверяйте VRAM и ollama ps после первого запроса.
Чем Ollama отличается от облачного API?
Ollama крутит модель у вас: нет платы за токен, данные не уходят к провайдеру. Облако даёт скорость и качество на больших моделях без покупки GPU. Для многих команд оптимален гибрид.
Как подключить ollama к n8n?
Создайте credential Ollama с Base URL http://localhost:11434 или http://host.docker.internal:11434 в Docker на Linux с extra_hosts. Прогоните тест соединения и один workflow с простым промптом.
Нужен ли ollama api key?
Для OpenAI SDK ключ обязателен в коде, но Ollama его не проверяет. Реальная защита – не ключ в Ollama, а сеть: localhost, proxy с auth, без открытого порта в интернет.
Можно ли заменить ChatGPT полностью на Ollama?
Для черновиков и внутренней классификации – часто да. Для юридических, медицинских и клиентских финальных текстов – нет без проверки человеком и fallback на облако.











