
Сайт уже собран в Cursor и залит на хостинг, а в Яндексе по-прежнему ноль страниц. Знакомая боль: в гугле десятки SEO-гайдов без привязки к вашему лендингу, страшно написать Disallow и закрыть всё одной строкой, а разница между robots.txt и sitemap.xml туманна. За один вечер вы соберите два текстовых файла в корне, сможете открыть их в браузере как обычные ссылки и настроите отправку карты в Вебмастер и Search Console.
robots.txt говорит роботу, куда можно заходить на обход, sitemap.xml перечисляет важные страницы. Попросите Cursor Agent собрать оба файла, залейте в корень домена и проверьте yoursite.ru/robots.txt и yoursite.ru/sitemap.xml. В robots.txt нужна строка Sitemap с полным https-URL, в карте не должно быть страниц, закрытых через Disallow.
Марина сверстала лендинг в Cursor, выложила на Vercel и через месяц увидела пустой индекс. В корне остался тестовый Disallow: / с чернового деплоя, sitemap она не создала. После гайда она попросила Agent собрать оба файла, проверила URL в Вебмастере и вместо «сайт закрыт» увидела зелёную галочку.
Контринтуитивный факт: robots.txt запрещает обход, но не гарантирует исчезновение из выдачи. Google и Яндекс пишут, что закрытая в robots.txt страница всё равно может попасть в поиск по внешним ссылкам — для удаления нужен noindex на странице. Ещё тихий конфликт: URL одновременно в sitemap и в Disallow, и трафик тает незаметно.
Разведите robots.txt и sitemap.xml без страха перед кодом

robots.txt — текстовая инструкция для роботов в корне сайта. sitemap.xml — карта с полными адресами страниц. Робот обходит сайт и решает, что показать в поиске; индексация — попадание страницы в базу поисковика.
На пальцах: robots.txt — табличка «сюда можно, туда нельзя». sitemap.xml — список важных комнат. Типичная ошибка — думать, что Disallow убирает страницу из выдачи. На практике он только просит не обходить URL; для удаления из поиска нужен meta noindex.
| Файл | Что делает | Чего не делает |
|---|---|---|
| robots.txt | Разрешает или запрещает обход | Не убирает страницу из поиска сам |
| sitemap.xml | Передаёт список URL и даты | Не отменяет Disallow на те же адреса |
Лимиты 2026 года: sitemap — до 50 000 URL и 50 МБ по Google. robots.txt только в корне хоста; Google обрезает после 500 КиБ, Яндекс — до 500 КБ без кириллицы в файле. Директива Sitemap в robots.txt принимает только абсолютный URL — это частая причина, почему робот «не видит» карту, хотя файл лежит на месте.
Честно говоря, путаница «закрыть от обхода» и «убрать из поиска» стоит тысячам сайтов месяцы без трафика. Запомните правило: Disallow для служебных папок, noindex для страниц, которые не должны светиться в выдаче вообще.
Откройте проект в Cursor и выпишите публичные страницы
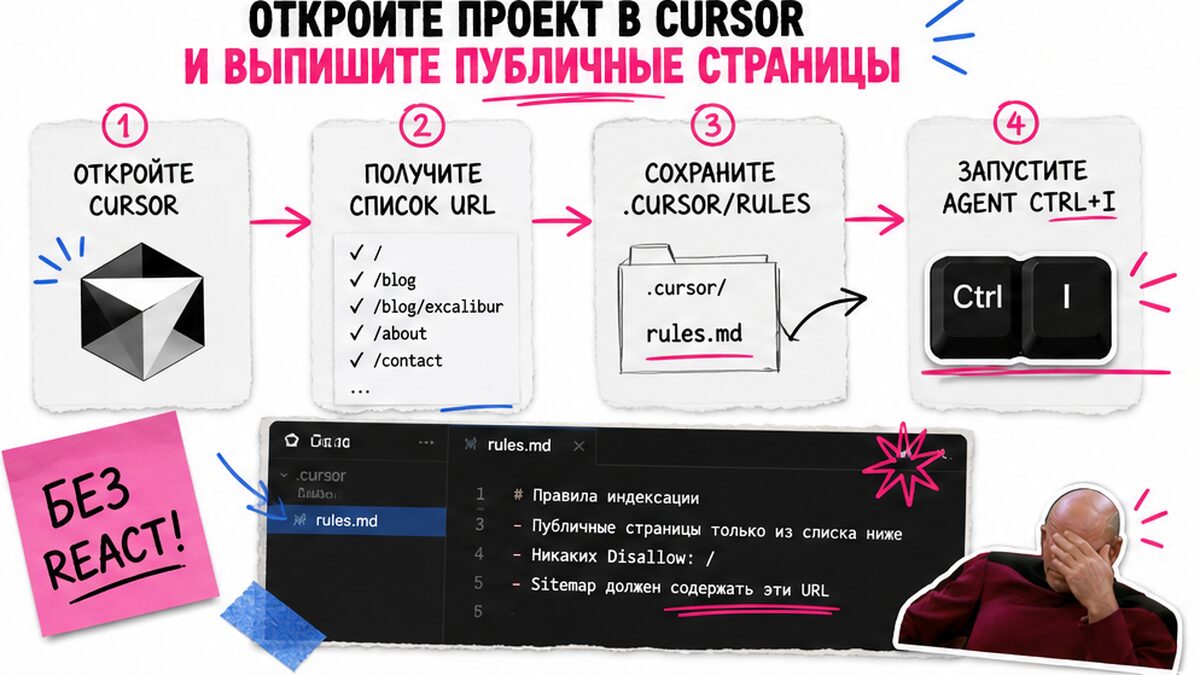
Часто Cursor тянет React и npm, когда нужны два текстовых файла. Задайте правило в .cursor/rules/: только статика в корне, без лишних фреймворков. Например, фраза «не добавляй package.json и не подключай фреймворки» в rules снимает половину типичных срывов Agent в сторону лишнего кода.
Для лендинга выпишите https-URL: главная, услуги, контакты, статьи. Не включайте /admin, /api и черновики. Для домена .рф используйте Punycode в файлах.
- Шаг 1: Откройте папку с index.html в Cursor.
- Шаг 2: Составьте список URL для поиска и отметьте папки для Disallow, например /api/.
- Шаг 3: Запишите канонический домен с https.
- Шаг 4: Переключитесь в Agent (Ctrl+I) с готовым списком.
В реальном проекте удобнее один раз попросить Agent и закоммитить файлы перед деплоем на Vercel, чем править XML руками после каждой новой страницы. На GitHub в 2026 году всё чаще встречается сборка robots и sitemap на этапе build. Вайбкодеру хватит двух промптов и проверки ссылки в браузере — как любого блока на лендинге.
Попросите Agent собрать безопасный robots.txt

Главный страх — Disallow: / и весь сайт невидим. Безопасный старт: User-agent: *, Allow: /, строка Sitemap с полным https-URL. Относительный путь в Sitemap робот не поймёт.
Промпт для Agent:
Статический сайт в папке. Создай robots.txt в корне.
User-agent: *
Allow: /
Disallow: /api/ (если папки нет — не добавляй)
Sitemap: https://МОЙ-ДОМЕН.ru/sitemap.xml
Без package.json и React. Покажи файл целиком.
Типичная ошибка: с теста на прод уезжает Disallow: /. Перед заливкой проверьте файл глазами — нет глобального запрета и кириллицы для Яндекса. При 404 на robots Google считает ограничений нет, кроме кода 429, но явный файл надёжнее. Если закрываете /admin или черновики, убедитесь, что главная и публичные разделы под Allow: /, иначе робот просто не дойдёт до контента.
Создайте sitemap.xml без URL из списка Disallow
В карту кладите только страницы, не закрытые в robots.txt. Совпадение URL в sitemap и Disallow — тихий убийца трафика в 2026 году.
Промпт для sitemap:
sitemap.xml по sitemaps.org в корне.
Все публичные HTML с полными https URL и lastmod сегодня.
Без URL из Disallow. UTF-8, до 50 URL. Покажи целиком.
Минимум: urlset и блоки url с loc. Для лендинга хватит 3-20 адресов; lastmod с датой обновления подсказывает роботу свежесть, но не даёт мгновенной переиндексации. Не дублируйте http/https и www/non-www — один канонический вариант, как на сайте. Уберите /thank-you, корзину, тесты и URL с ?utm=. После генерации сверьте список с рукописным: карта отражает то, что хотите показать клиенту, а не технический мусор репозитория.
Проверьте ссылки в браузере и отправьте карту в Вебмастер
Успех простой: оба URL открываются с кодом 200, в robots.txt есть Sitemap, панели принимают карту без «заблокировано robots.txt».
Схема:
Деплой → браузер (оба URL) → Яндекс: Анализ robots.txt + Файлы Sitemap → Google: Search Console → Sitemaps
- Шаг 1: Залейте файлы в корень хостинга или через commit с автодеплоем.
- Шаг 2: Откройте адреса в браузере — текст и XML, не HTML-ошибка.
- Шаг 3: В Яндекс Вебмастере — Инструменты → Анализ robots.txt.
- Шаг 4: Добавьте URL sitemap в разделе Файлы Sitemap.
- Шаг 5: В Search Console отправьте sitemap и проверьте главную через URL Inspection.
Яндекс не обработает sitemap, если сам файл карты запрещён в robots.txt. Ошибки в панелях должны исчезнуть сразу; переобход сайта займёт дни. Критерий «всё сработало» до FAQ: оба URL отдают 200, строка Sitemap в robots.txt указывает на живую карту, в sitemap нет адресов из Disallow, Вебмастер и Search Console приняли файл без красных предупреждений о блокировке.
Избегите шести ошибок, которые режут индексацию
- Disallow: / на проде после тестового деплоя.
- URL в sitemap совпадает с Disallow.
- Нет строки Sitemap в robots.txt.
- Кириллица внутри robots.txt — Яндекс не примет.
- Блокировка CSS/JS — Google хуже рендерит страницу.
- Дубли http/https и www в sitemap.
Когда пара файлов работает, добавьте llms.txt для AI-агентов и сверьте meta-теги через Cursor. Общая картина GEO — в чек-листе geo-оптимизации.
Если sitemap нужно обновлять после каждой статьи, автоматизируйте через Make.com: новая строка в таблице → пересборка XML → деплой. Подробнее — в курсе Make.com и вайбкодинга; два файла через Cursor вы сделаете за вечер без разработчиков. Вопросы по связке Cursor, хостинга и вебмастеров можно разобрать в Telegram «Ковчег».
Материал проверен: Артур Хорошев, CEO Maya AI, автор курса по Make.com и вайбкодингу.
На что опираемся: лимиты sitemap и robots.txt — developers.google.com; правила Яндекса — yandex.ru/support/webmaster; конфликты sitemap vs Disallow — rankai.ai, seoable.dev; частотность «robots txt sitemap» (156), «robots txt для сайта» (244), «создать sitemap xml» (70) — Яндекс Вордстат, 29 июня 2026.
Частые вопросы
Где должен лежать файл robots.txt?
Только в корне: https://ваш-сайт.ru/robots.txt. В подпапке роботы не ищут главный файл. После деплоя откройте адрес и проверьте код 200.
Как указать sitemap в robots txt?
Строка Sitemap: https://ваш-сайт.ru/sitemap.xml с полным https. Дублируйте загрузкой карты в Вебмастер и Search Console.
Чем отличается sitemap xml от robots txt?
robots.txt управляет обходом, sitemap.xml перечисляет страницы для индексации. Первый — «куда не ходить», второй — «что важно проиндексировать».
Как проверить robots txt онлайн?
Откройте URL в браузере и зайдите в Яндекс Вебмастер: Инструменты → Анализ robots.txt. В Google — отчёт robots.txt в Search Console.
Закроет ли Disallow страницу в поиске?
Нет, только ограничит обход. Для удаления из выдачи поставьте noindex на странице или закройте индексацию в панели вебмастера.
Нужен ли sitemap для маленького лендинга?
Для 3-10 страниц карта не обязательна по правилам, но сильно упрощает жизнь: робот быстрее находит все URL, а в панели видно, если страница заблокирована robots.txt. Создать файл в Cursor — около 10 минут, дешевле месяца ожидания в пустой выдаче.











